什么是 Tokens?
发生了什么?
当我们发送一个 Prompt 给 ChatGPT 的时候,发什么了什么?它是如何返回结果的?为什么结果总是不一样的?
Hello, ChatGPT.Hello! How can I assist you today?这里就不得不提到 GPT 重要的两个概念:tokens(标记) 和 probability(概率)
人类是如何思考的?
现在,大家忘记其他的东西,跟我一起来思考一个问题,那就是:人类是如何说话的?
我们先来看一个例子,这里有一段话:
如果你突然现在我让大家把这段话补充到 10 个字,你会怎么做?
大家可以 思考 一下...
然后把你的答案打在屏幕上或写在纸上 ✍️
假如我们有 张三 和 李四 两位朋友,他们两个分别给出了下面的答案:
如果你突然打了个喷嚏如果你突然变成一只猫你会发现,他们两个的答案都符合我的要求:将 如果你突然 变成 10 个字的一句话,但他们的答案却各不相同。
为什么?
因为 随机性,你会发现人类在说话和写作的时候,会有一个思考的过程,总是一个字一个字或一个词一个词的思考。
标记
当、我在、写、这段话、的、时候、我、也是、一个、字、一个字、的、思考、的
当、我、在写、这段话、的、时候、我也是、一个字、一个字、的、思考的
我把一句话写了两次,并没有刻意去控制自己的思维,只是在我思考停顿的时候,打下了一个 “顿号”,于是你看到两次打的话,停顿处不一样。
我们可以把每个顿号前面的字,看成一个 标记,我们每次思考都是基于当前已有的内容,思考下一个标记最应该是什么。当然这取决于我们的知识储备,因为标记都来源于我们的知识储备。如果我们从来都没有见过或听过一个词,那我们是不可能想到去使用它的。
而且这个过程具有很大的随机性。
随机性
假如我们再让张三写一次上面的话,告诉他忘记刚才的内容,任由他想到什么就写什么,他可能会写:
如果你突然出现在这里张三给出了不同的答案,当然他也有可能还是给出上一次的答案。我们不是张三,并不知道他会如何选择,因为结果是 “随机” 的,他自己都不知道结果是什么。
但可以肯定的是,张三只能基于自己的 知识储备 来说话,如果他知识库中没有这些东西,他可能就会 “瞎编”。
人类的说话过程
那我们是否可以理解为,可以分为三个步骤:
-
拥有足够多的知识储备,至少掌握一定的词汇和句子 (这些词汇和句子,在我们的大脑深处会被拆分成一块一块的标记,等待我们使用)
-
看到一句话,接着这句话往后说的时候,会根据这句话去大脑中搜索,哪个标记最应该出现在这句话后面
-
可能有很多标记都符合条件,此时我们会 “看心情” 选择一个 (也就是随机选一个)。
此时大家可以停下来,思考一下,是否是这样的?
同时可以完成下面三个小练习,同样需要你写在纸上或打在屏幕上。
快来练习一下吧,在这个过程中要注意感受大脑是如何思考的 🤔
我的老家,就我今天在gptpmt ...因为 ... 所以 ...非常好,现在你已经完全理解 ChatGPT 的“模式”了 🎉
是的,ChatGPT 也是这么工作的
ChatGPT 将它所理解的一个个的“字”和“词”,称为 标记(token)
一个简单的英语语法知识,复数形式要加 “s”,所以 一个 token,两个 tokens。
ChatGPT 原理
Token
以上面打的这句话为例子 当、我在、写、这段话、的、时候、我、也是、一个、字、一个字、的、思考、的
这些停顿是如何产生的?为什么会有这些停顿的字词?
答案是我们的大脑会根据过去接触过的知识进行自动分割,比如我们看到了一个成语,记住以后下次总会直接说出这个成语,但如果是一句较长的话,我们可能使用的时候就是说一段,想一段。
GPT 也是这么做的,我们都知道 GPT 是一个使用很多数据训练出来的模型,由于 GPT 是一个语言类的模型,所以我们给它输入的都是文字类的资料。当 GPT 接收到资料的时候,会跟人类一样,将这些段落和句子划分成一个个独立存在的 “字词”,可以理解为语言的最小单位。
GPT 将这种最小单位称为 token,人类任何一门语言都有这种最小的语言单位,例如:英语中的单词,中文的单字等等。
当然,GPT 内部有自己独特的 tokens 分割逻辑,因为它几乎要处理世界上所有的语言,那每个语言的文字都是不同的,它需要有一种更高级和更适合机器理解的分割方法。不能简单的按照英语的一个单词,中文的一个单字这样来划分。
ChatGPT 如何进行 tokens 分割?
来看 ChatGPT 官方提供的 tokens 分割查询工具:https://platform.openai.com/tokenizer (opens in a new tab)
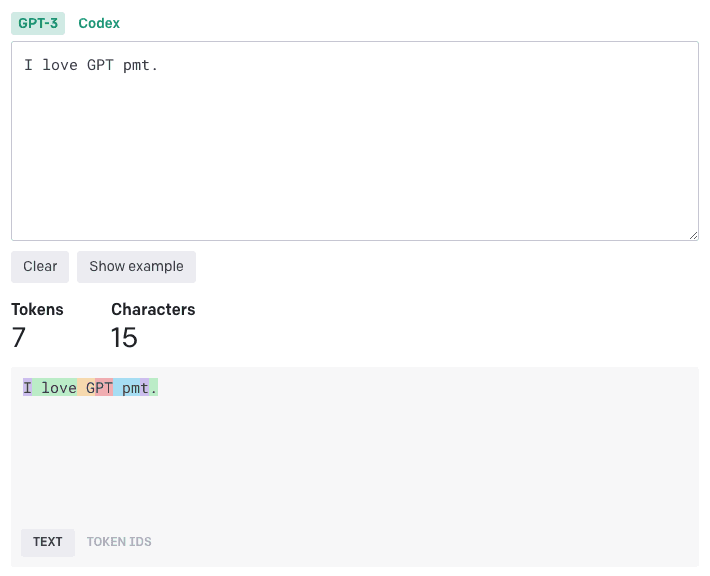
我们输入了一句英语:I love GPT pmt.
这其中包含字母 I,空格,单词,以及一个 . 号
分割结果显示一共有 15 个字符(每个 字母、空格、.号、就算 1 个字符,刚好 15 个字符),7 个 token。而且我们可以看出它的分割逻辑非常的神奇,它没有直接把每个单词或者是单个字母划分成一个 token,而是用了一种看似很复杂的方式。
它有 I 这样独立一个字母的 token,也有 love 这种前面带了一个空格的 token,还有 G 这种一个字母前面带了一个空格的 token,也有 PT 这样的两个字母组合的,还有单独一个 . 号的。
为什么会这样?
如果要深究这个原理,我们可能就要有一个很大的篇幅来进行讲解,而且对于没有算法基础的朋友来说,可能也不太容易理解。
GPT使用了一种 Byte Pair Encoding(BPE)的算法进行tokens分割,它将文本中最常见的字符或字符组合分割为独立的token。
需要注意的是,BPE 算法不是完全基于字符的切分方法,而是根据字符的频率进行子词切分。它通过不断的合并出现频繁的字符或字符组合来构建词汇表。在这个过程中,字符可能会被合并成更大的单元,这样可以更好的表示复杂词汇和短语。简单理解就是:GPT 跟人一样,它会把看到的文字按照出现频率分割成一个最小单元,这个最小单元就是 token,而分割使用的算法就是 BPE 算法。
感兴趣的可以阅读维基百科的说明:https://en.wikipedia.org/wiki/Byte_pair_encoding (opens in a new tab)
恭喜 🎉 你已经理解 GPT 最核心的原理了~
但是...
水土不服的 ChatGPT
先别急着高兴,我们遇到了一个略微复杂的问题,那就是:中文如何处理?
大家可能会想:这还不简单,那肯定是一个字或者一个词这么分割的啊。
真的是这样吗?
大家可以想想前面的单词 GPT 可以被劈成两半 分成了 G 和 PT,那中文怎么劈成两半呢?
而且如果真劈两半那我们还能认识这个字吗?就比如 爱 字。
还是以 I love GPT pmt. 直接翻译为中文,让 ChatGPT 分割 tokens 看看会发生什么:

结果显示有 11 个字符:一个汉字、字母、空格、标点符号,都表示一个字符,刚好 11 个。
Token 有 10 个,但是下面的字符怎么有一些是一个菱形的问号,看不懂是什么?
还记得我们前面说的 “把汉字劈开” 的玩笑吗?GPT 真的把汉字 “劈开” 了。
大家可能会觉得不可思议,汉字本身当然不可能直接劈开了,但是如果把汉字转换成另一种形式,比如 UTF-8 编码,那么就可以“劈开”了。
以下内容仅做了解:
以下内容来自ChatGPT:
当我们说到中文字符在 BPE 分词中的表现,需要先了解一些编码的基础知识。在计算机中,中文字符通常使用 Unicode 编码,而 Unicode 字符在计算机中是通过 UTF-8 编码进行存储的。UTF-8 编码是一种变长的编码方式,也就是说,不同的字符可能需要不同数量的字节进行表示。对于常见的 ASCII 字符,UTF-8 编码使用 1 个字节进行表示;对于某些特殊的拉丁字母,可能需要 2 个字节;对于大部分的中文字符,UTF-8 编码需要 3 个字节。
假设我们有一个中文字符 "家",它的 UTF-8 编码是:E5 AE B6,这是 3 个字节。当我们使用 BPE 对这个字符进行分词时,如果 BPE 的词汇表中没有 "家" 这个字符,但是有这 3 个字节的一部分,那么 "家" 可能会被拆分成几个部分。比如,它可能被拆分成两个 token,第一个 token 对应 UTF-8 编码的前两个字节 E5 AE,第二个 token 对应 UTF-8 编码的最后一个字节 B6。这就是中文字符在 BPE 分词中可能会被 "乱码" 的原因。
然而,实际上在 GPT-2 和 GPT-3 的训练过程中,词汇表是通过在大量的文本数据上运行 BPE 算法得到的,这些文本数据包括各种语言,包括中文。因此,词汇表中应该包含许多常见的中文字符,这样就可以避免将一个中文字符拆分成多个字节。但是,对于那些在训练数据中很少出现的字符,可能还是会出现被拆分的情况。
总的来说,中文字符在 BPE 分词中可能会被拆分的原因是:
- 这个字符在词汇表中不存在
- 这个字符的 UTF-8 编码可以被拆分成词汇表中存在的几个部分.这可能会导致一个中文字符被表示为一串无法直观理解的 token,但是对于模型来说,这些 token 仍然有意义,因为它们可以被正确地转换回原始的字符。
简单来说就是:汉字被“劈开”了,而且“劈”的份数还不一样
“我” 字,被分成了 2 个 token:

“爱” 字,被分成了 3 个 token:

不难发现,同样意思的内容。英文 7个tokens,中文10个tokens,使用中文tokens会多一些。(以后会再提到这个知识点)
Token IDS
值得一提的是,ChatGPT 在分割完 tokens 后,会给每个 token 分配一个唯一的 数字编码,就跟身份证一样,通过这个数字编码我就能找到对应的那个 token。
看一下 我爱 GPT pmt。 的每个 token 的 id 是什么:

可以看到一共 10 个数字编码,那按我们前面的理解 22755, 239 这两个代表的应该就是 “我”:

果然!
恭喜你 🎉,真正掌握了 GPT 最核心的概念 Tokens 和 Token IDS。你已经理解了 GPT 背后工作的原理,这对于我们后面的课程,至关重要。
恭喜学完本章节,欢迎到 Github issues (opens in a new tab) 发表学习心得以及反馈问题 👏🏻
